|
|
马上注册,结交更多好友,享用更多功能,让你轻松玩转社区。
您需要 登录 才可以下载或查看,没有账号?注册
x
随着时代的发展,存储、计算和处理技术手段的跃进可以使得人们运用更跳跃的想象,从更多维的视角对研究对象提出更野心的诉求。
大数据之“大”
“大数据”之“大”并不在于数据量绝对意义上的“大”,而是相对于“部分采样”只能采用部分数据量的情况,“大数据”时代允许研究人员可以利用研究对象尽可能多的数据,甚至是所有的数据针对研究对象进行分析。
此前数百年的科技、财力和人力限制,很多调查并不能涉及到所有的调查对象,故而随机采用被广泛运用各行各业,如电视节目收视率调查、街头路人采访、民调指数调查、工业产品质量抽检、行业调研等,“部分采样”的思路已经习以为常,被大家奉为圭臬,导致很多在此前数十年堪称标准的思想:
1.变量少,低维度:如因为计算能力的受限,变量不能太多,所以做事要分清主要矛盾和次要矛盾,尽可能地专注于参量较少的主要矛盾;
2.测量精确:因为模式变量较少以及采样样本较少,故而对测量精确性有着近乎严苛的要求,因为测量的不精确度会被成倍地放大;
3.因果推断:但是有时候和第二点矛盾的是,相比于在测量时务求精确,无论是传统工业界或是学术界都对直接复杂输出结果的数学模型的准确性没有多少要求,却专注其可适范围尽可能广。
但是相比于数理领域的至简至洁的逻辑美感,其他领域一个模型吃遍所有定义域的这种表现形式会给人造成强烈的因果关系错觉,并将结果的偏离归结于现实环境的不确定性和噪声干扰,所以导致很多学术界都存在这样一个“共识”:模型要尽可能简单,同时适应性(鲁棒性)较强,并且最为关键的是模型可解释(因果推断思想的着重体现),而模型可解释的思路在现今的深度学习等热门技术前线都是不可行的。
某种程度上,可能也是因为此前测量成本高、计算能力不足导致推导一个目标模型的成本较高,故而一旦得到一个较好的目标模型总是尽可能地扩大其可以覆盖的对象范围,在诸多学术机理依旧没有很好的研究发现的情况下,这种面对面的映射可能在过去是无奈之举,结果也是可以被接受的。但是在现今诸多领域的竞争已经进入毫秒、微米甚至1%量级的差异挑战时代,这种面对面的映射无疑是较为粗糙的。
技术上的三驾马车
“大数据”时代真正来临在技术上主要是三驾马车依次被实现:数据仓库、联机分析技术和数据挖掘。
1.数据仓库:数据仓库相比于传统已有的关系型数据库最大的区别是数据仓库是以数据分析、决策支持为目的来组织存储数据,而数据库则是为运营系统保存、查询数据。
浅显点举个例子——你开了一个小便利店,每天假设有100笔不同交易,每个小票代表一笔交易,出于方便记录和查询考虑,你找个小篓子将每笔小票收集起来,那么这个小篓子类似数据库的功能,一旦有顾客过来退换物品,甚至要求补贴差价,你便可以去篓子找到相应顾客的那笔交易的小票,并根据小票记录的流水确定用户是否确实购买了相应的商品,以及是否存在价格出错等问题。
如果你是个有野心的老板,这种简单的小票收集并不能对于你开店进货、上下架、货物捆绑销售起到指导作用,于是你每天在小店关门后,将当天篓子里所有的小票收集起来,将一天划分为7:00-8:00(上班高峰)、9:00-11:00(早上正常营业段)、11:00-1:00(中午白领休息时段)、1:00-5:00(下午正常营业段)、5:00-7:00(下班高峰)和7:00-10:00(夜间营业段)六个时间段,计算各物品在各时间段售出总额,以及每笔交易的购物篮所有物品等,那么你可能会发现在7:00-8:00上班高峰段牛奶和吐司出现了一天最高的销售量,并且这两物品经常出现在同一个购物篮中,那么将牛奶和吐司捆绑作为早餐套餐摆在店面显眼位置很可能会帮助你取得更好的销售效果……
故而数据仓库相比于数据库,多了一层加工计算的过程,虽然这一步看似简单,但是如何设置尽可能多的维度(如时间段划分更细、商品分类、天气等)并保证数据仓库有尽可能多的扩展性,想象下你可以绘制一个三维坐标(时间段:2016.8.20. 10:00-11:00、主物品:汽水、辅助因素:天气温度38度酷热),但是如果是四维坐标呢?比如加入另一个搜索维度:汽水品牌可口可乐(或是百事可乐甚至是激浪),可以想象这种多维度并且要求极大扩展性的数据结构是很难设计和维护的。故而数据仓库技术的成熟是实现多视角统筹分析的硬件基础,它让繁杂的数据单元被高度有序地整合,从而利于分析者拥有上帝视角。
2.联机分析技术(Online analytical processing):则是跨部门、跨不同数据库的数据整合。
比如将商场交易的数据库和商场停车场的人员进出数据库进行整合,说不定可以得出停车场中停留时间在1-2h内的用户可能有更强的购买意愿,而停车时间达到3h以上的用户反而购物总额较少(说不定人家就是来吹空调的),所以合理的调控停车场收费策略可能会带来更多收入。
联机分析处理的概念最早由关系数据库之父E·F·Codd于1993年提出的。Codd认为联机事务处理(OLTP)已不能满足终端用户对数据库查询分析的要求,结构化查询语言(SQL)对大数据库的简单查询也不能满足用户分析的需求。用户的决策分析需要对关系数据库进行大量计算才能得到结果,而查询的结果并不能满足决策者提出的需求。因此,Codd提出了多维数据库和多维分析的概念,即OLAP。
OLAP委员会对联机分析处理的定义为:使分析人员、管理人员或执行人员能够从多种角度对从原始数据中转化出来的、能够真正为用户所理解的、并真实反映企业维特性的信息进行快速、一致、交互地存取,从而获得对数据的更深入了解的一类软件技术。
OLAP的目标是满足决策支持或多维环境特定的查询和报表需求,它的技术核心是“维”这个概念,因此OLAP也可以说是多维数据分析工具的集合。但是这种跨平台、跨系统的数据整合调用,涉及到诸多机理性问题,如数据一致性问题(如何判断停车的人和某个购物篮主人是一个人?)
3.数据挖掘:点石成金的关键,发现数据规律的手段
数据仓库和联机分析技术可以说是提供了分析的硬件基础,但是如何将这些数据进行转化分析得到类似“啤酒与尿布”这种堪称“零售业小知识”的关键则是依靠数据挖掘算法对数据进行凝练提取,如物品相关性分析(交叉销售)、店内行为分析(沃尔玛通过给购物车安装射频发射器,货架安装非接触式射频接收器,利用RFID(radio frequency identification)技术得到顾客在超市在商场内行走轨迹和物品购买顺序,从而利于其商场的布局进行更合理的设计)等。
数据挖掘主要是两个作用,一个是描述性分析,即针对过去,揭示已经存在的规律,如“啤酒经常和尿布一起被年轻爸爸购买”的事实;二是预测性分析,面对未来,预测趋势(如7+11有所谓的可乐天气指数,各门店可以根据天气数据提前进行库存调整)。
其实呢,“大数据”时代现在是四驾马车,还有一个叫做数据可视化,就是经常看到那种关于大数据应用经常看到的动态图,颜色缤纷,形象易懂,这个也是个很考验设计人员美学素养的活,好看且让人易懂。
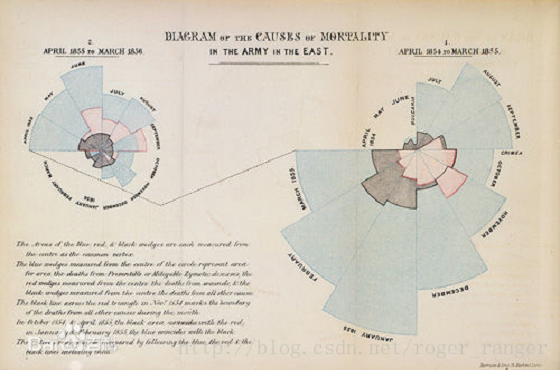
生理学上来说,人大脑皮层40%是视觉反应区,人类神经系统天生对图像化信息最为敏感,通过图像可以将信息的表达和传递更加直观、快捷和有效,正所谓创造力是:逻辑思维plus形象思维,好看的数据图可以激发分析更多的想象力。插个话,数据可视化的鼻祖是南丁格尔,对!就是那个历史上最有名的护士。下图便是有名的南丁格尔玫瑰图,她将战斗减员(深色小扇形)占战场伤亡总人数(大扇形)的比率很形象的进行展示,可以看到大多人员伤亡并非来自战场的直接伤亡,而更多的是来自不必要的因素(主要因素便是战场护理不到位,导致感染死亡),并促使高层下定决心成立战场医院。
(未完待续......)
|
|


 IP卡
IP卡 狗仔卡
狗仔卡 发表于 2019-11-12 17:31:38
发表于 2019-11-12 17:31:38
 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 显身卡
显身卡
